@PPO中有了reward model 为何还要有critic model?
链接: PPO总有了reward model 为何还要有critic model? - 知乎
问题 #card
如果是reward model 可以对response 做出评价? 那这个评价如何对应到token level loss上?
如果reward model 能够给出token level loss,为何还需要critic model 给一个类似的token level loss 呢?
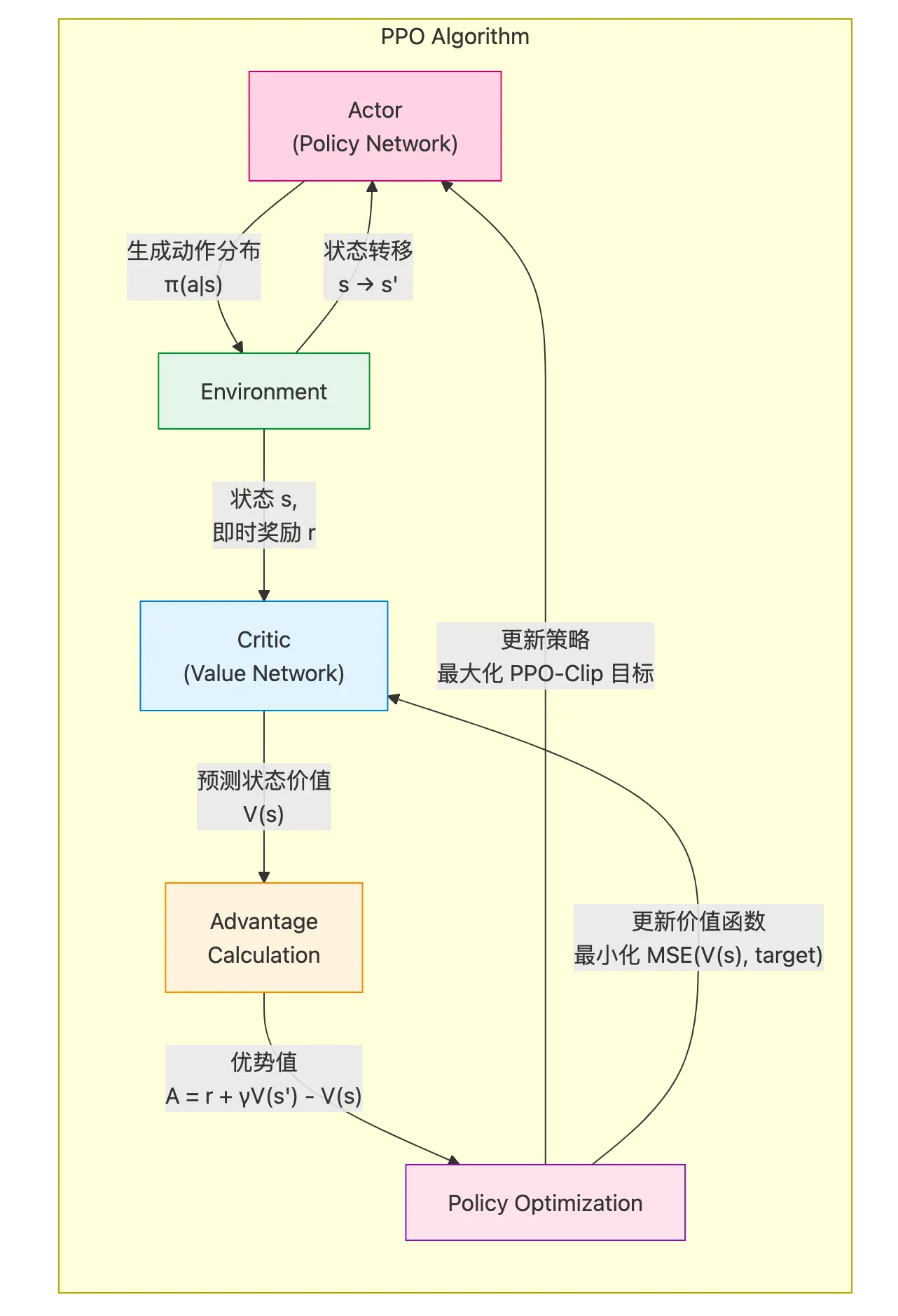
传统 PPO 中的 RM 在哪里? #card
- 这里「环境」就是 RM,它负责建模智能体外部的世界,给出「奖励信号」。
[[reward model]] 在 LLM 应用环境中,我们应用 PPO 算法,是把 LLM 当成智能体,但什么是环境呢?似乎不像下围棋、玩游戏这种传统 RL 场景中那样容易定义,奖励从何而来呢?#card
- 那我们就训练一个 RM 来充当这样角色,它最主要的目标就是给 LLM 这个智能体以 「奖励信号」,这个奖励代表了 LLM 的决策(输出响应)有多符合人类的期望或偏好。
Critic 是 LLM 这个智能体的「内部组件」,它的任务是#card
估计在某个特定状态 s 下,遵循当前策略 T从该状态出发所能获得的未来累积奖励的期望值。
其实就是价值函数 $V(s)=E\left[\sum \gamma^t * r_t \mid s_0=s, \pi\right]$ 对,其中Y是折扣因子。
Critic 是智能体的一部分
- 如果你对 Actor-Critic 这个经典的 RL 框架有所了解,那就很容易理解了,PPO 就是采用了 Actor-Critic 框架的一种算法,其中 Critic 的作用就是 :-> 计算 优势函数 (Advantage Function),从而减少策略梯度估计的方差,使训练更稳定、高效。
- RM 是 外部的奖励信号,是外部环境给与智能体的真实响应 ——虽然在 LLM 的这个场景里,我们没有特别准确的外部环境建模,退而求其次用另一个训练好的 RM 模型来代替了——而 Critic 是 智能体内心对自己答案的评价 。
不用 Critic 行不行?
- 确实可以,其实在 Actor-Critic 框架之前,RL 算法就是这样的,不要「基线」了而已。代价就是 **方差比较大,训练不稳定 ** 。
- 近来 LLM 领域的 RL 后训练里,会经常使用一种叫做 GRPO 的算法,是对 PPO 的一个改良。它其实是通过另一种更简单的「估算基线」的方法,取代了 Critic:就是 :-> 采样多次,用 RM 评价的平均值来充当这个「基线」。
Critic 不是提供额外的奖励来源,而是 通过学习预测未来的期望回报 ,提供了一个动态的基准,用来校准 RM 提供的原始奖励信号,生成更稳定、信息量更大的 Advantage 信号,从而稳定并加速 PPO 的训练。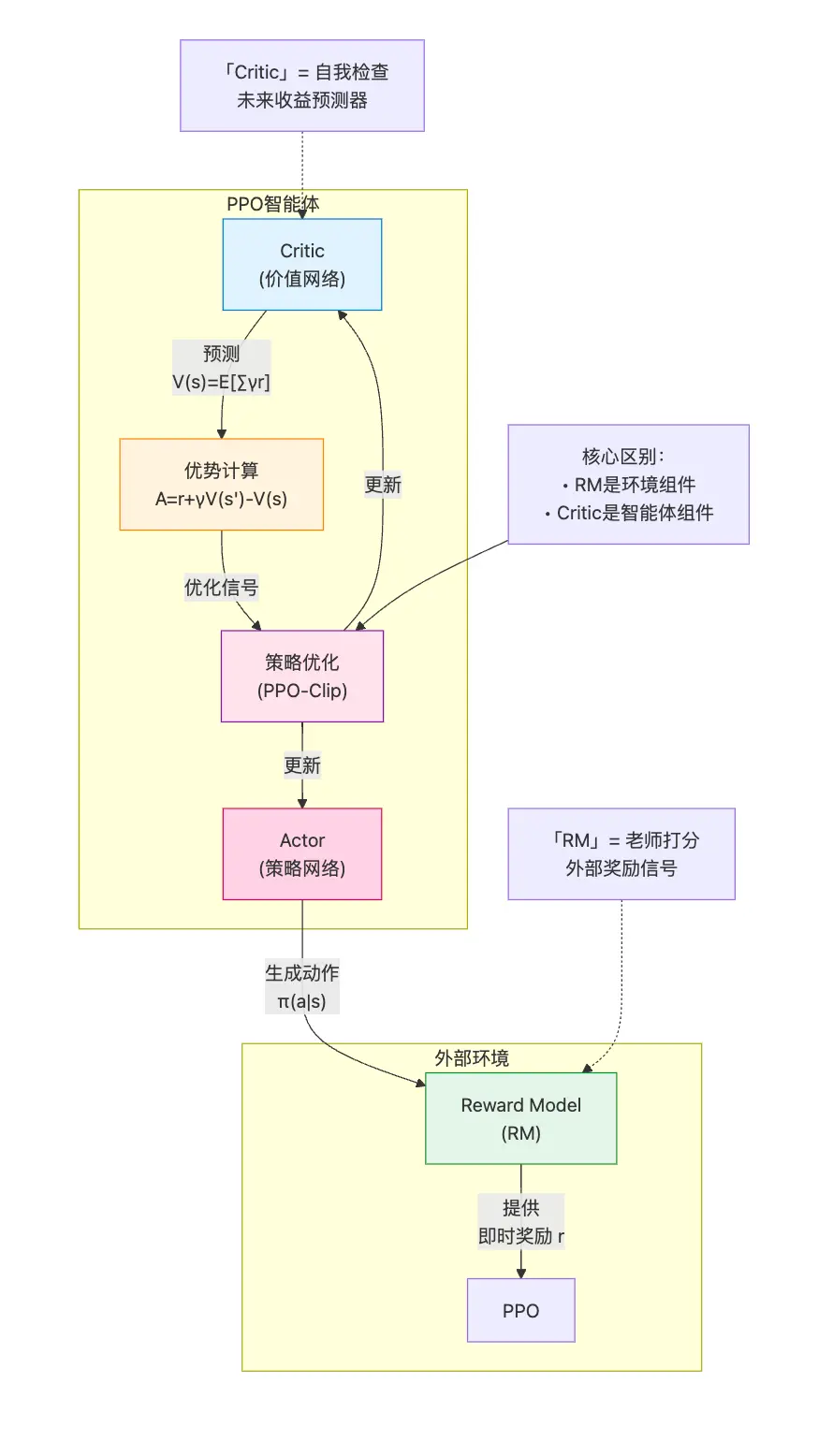
occlusion:: eyIuLi9hc3NldHMvaW1hZ2VfMTc0OTk4NTg5Njg3NV8wLnBuZyI6eyJjb25maWciOnt9LCJlbGVtZW50cyI6W3sibGVmdCI6Njc3LjYxNTg2MDA4Nzk5MzIsInRvcCI6NTU5Ljk0MTQwMDIyODQ2MzcsIndpZHRoIjoyMTguNjU4NTg5NDU2NjQ4NSwiaGVpZ2h0IjoxMTAuNDk3NDAzMTAzMjExODEsImFuZ2xlIjowLCJjSWQiOjF9LHsibGVmdCI6NTU0LjkzODg2NDU4MTQ2MjksInRvcCI6MTE5OS44Mzk1OTY0NzQzMjQsIndpZHRoIjoyMTcuNjUxNjQ3NDYzMDE4NywiaGVpZ2h0IjoxMTcuMDA4ODA3NDIzMzgyNDUsImFuZ2xlIjowLCJjSWQiOjJ9XX19
@PPO中有了reward model 为何还要有critic model?
https://blog.xiang578.com/post/logseq/@PPO中有了reward model 为何还要有critic model?.html